








配列結合で困ったことはありませんか?
Power Automateで複数のデータソースから取得した配列を1つにまとめたい、そんなシーンは実務でよくありますよね。例えば、営業部と開発部の勤怠データを別々のシステムから取得して、レポート用に統合したい場合などです。
そんな時、多くの方がunion関数を使われるかと思います。確かに便利な関数なんですが、実は重複を自動削除してしまうという特徴があるんです。兼務している社員のデータが両方の配列に含まれている場合、重複が削除されて全件を取得できません。
では、重複も含めて全件をそのまま結合したい場合はどうすればいいのでしょうか?
解決策:Selectアクションを活用する
方法はいくつかありますが、今回ご紹介するのは、データ操作の「選択」アクションを使った方法です。Apply to eachを使わずに、たった1つのアクションで配列を全件結合できます。
今回使用するデータ
まず、今回の例として以下のようなデータを用意しました。各「作成」アクションで5件ずつ、合計10件のデータを用意しています。
営業部の勤怠データ(5件)
[
{"社員ID": "EMP001", "氏名": "山田太郎", "部署": "営業部", "出勤時刻": "09:00", "退勤時刻": "18:30"},
{"社員ID": "EMP002", "氏名": "佐藤花子", "部署": "営業部", "出勤時刻": "08:45", "退勤時刻": "17:50"},
{"社員ID": "EMP003", "氏名": "鈴木一郎", "部署": "営業部", "出勤時刻": "09:10", "退勤時刻": "19:00"},
{"社員ID": "EMP004", "氏名": "田中美咲", "部署": "営業部", "出勤時刻": "08:55", "退勤時刻": "18:15"},
{"社員ID": "EMP005", "氏名": "高橋健太", "部署": "営業部", "出勤時刻": "09:05", "退勤時刻": "18:45"}
]開発部の勤怠データ(5件、一部重複あり)
[
{"社員ID": "EMP003", "氏名": "鈴木一郎", "部署": "営業部", "出勤時刻": "09:10", "退勤時刻": "19:00"},
{"社員ID": "EMP005", "氏名": "高橋健太", "部署": "営業部", "出勤時刻": "09:05", "退勤時刻": "18:45"},
{"社員ID": "EMP101", "氏名": "伊藤翔太", "部署": "開発部", "出勤時刻": "10:00", "退勤時刻": "19:30"},
{"社員ID": "EMP102", "氏名": "渡辺愛美", "部署": "開発部", "出勤時刻": "09:30", "退勤時刻": "18:20"},
{"社員ID": "EMP103", "氏名": "中村拓海", "部署": "開発部", "出勤時刻": "10:15", "退勤時刻": "20:00"}
]実装方法を詳しく解説
基本的な考え方
この方法を一言で説明すると、2つの配列の長さを足した分のインデックス配列を作成し、そこから順番に各配列の要素を取り出していくという仕組みです。
ポイントは以下の2つになります:
- **元(from)**でインデックス配列を作成
- **マップ(map)**で条件分岐して適切な配列から要素を取得
手順1:インデックス配列を作成する
まず、「元」の部分でインデックス配列を作成します。ここで活用するのがrange関数です。
range関数は、指定した数の値だけ数値の配列を作成する関数で、1つ目の値には始まりの数値、2つ目の値には何行作成するかを指定します。
今回は以下のような式を記載します:
range(
0,
add(
length(outputs('作成')),
length(outputs('作成_1'))
)
)
始まりの数値は0とし、作成する行数は結合したい配列の合計の行数となります。配列の行数はlength関数でそれぞれ取得し、それをadd関数で加算することで取得できます。
なぜ0から始めるのか?
配列のデータを取り出す場合、最初の行を取得したい場合は1からではなく0から始まるため、このような配列を作成しています。
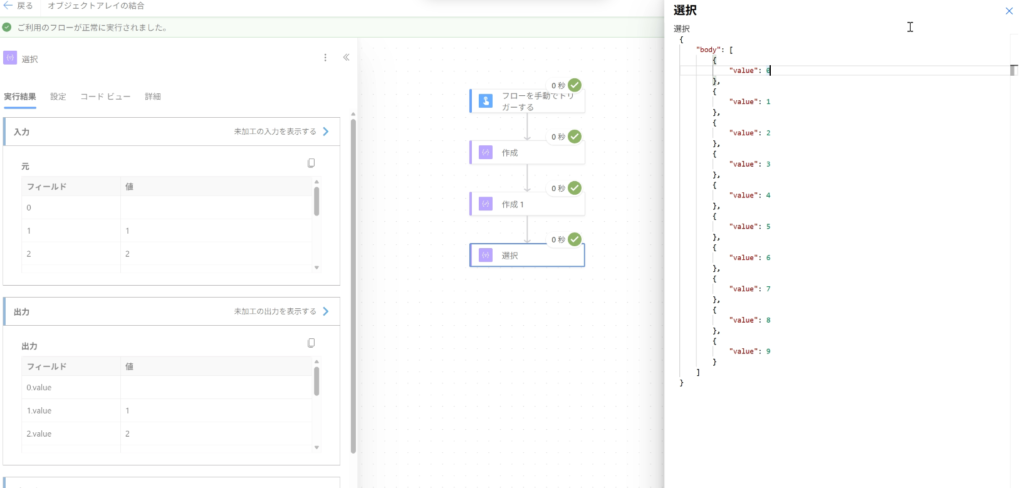
この時点でどのような値が出力されているのかを確認するために、マップに対してitem関数で値を表示するようにしてみると、このように0から9までの10行のデータが作成できていることがわかります。
手順2:条件分岐で要素を取り出す
item関数を使うとインデックス配列の数値も取得できることがわかったので、あとは条件に応じてそれぞれの配列からデータを抜き出すような式を記載します。
マップをテキストモードに変更して、すべての値を削除し、以下の式を記載していきます:
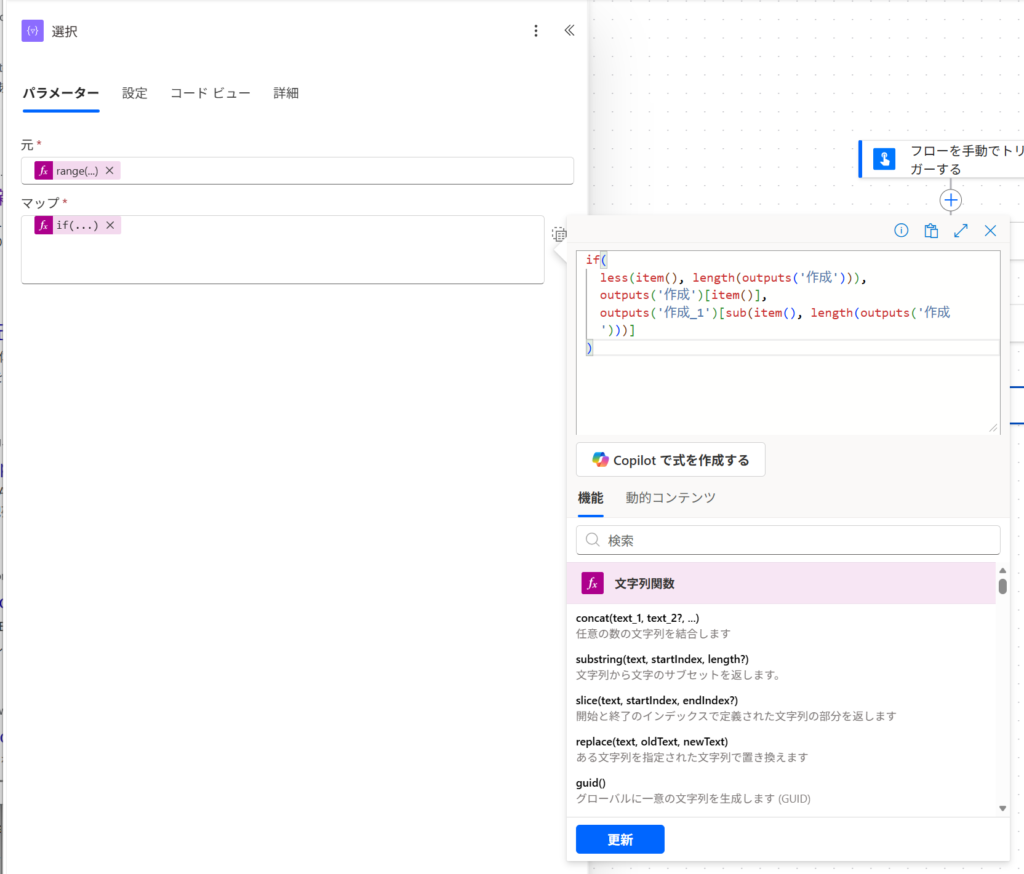
if(
less(item(), length(outputs('作成'))),
outputs('作成')[item()],
outputs('作成_1')[sub(item(), length(outputs('作成')))]
)式の詳しい解説
今回は2つの配列それぞれからデータを取得する必要があり、どちらの配列から要素を取り出すかを判定するために条件を記載します。
条件判定部分
less関数を使って、現在のインデックスが1つ目の配列の長さより小さいかチェックし、小さければ最初の配列から、大きければ2つ目の配列から取り出すようにします。
less(item(), length(outputs('作成')))Trueの場合(1つ目の配列から取得)
結果がtrue、つまり1つ目の配列から取得する必要がある場合は、item関数を使ってそのまま要素を抜き出します。
outputs('作成')[item()]Falseの場合(2つ目の配列から取得)
結果がfalse、つまりインデックスが5以上で、2つ目の配列から抜き出す必要がある場合は、そのままでは取得できないので少し工夫します。
sub関数を使って1つ目の配列の長さを今のインデックスから減算します。
outputs('作成_1')[sub(item(), length(outputs('作成')))]なぜ減算が必要なのか?
例えばインデックスが5の場合、5から5を引いて0にすることで、2つ目の配列の最初の要素(インデックス0)を取得できるようになります。同様に、インデックス9なら9-5=4で、2つ目の配列の最後の要素(インデックス4)を取得できるわけです。
動作確認
これで完成なので、フローを保存し、テストから動作を確認してみましょう。
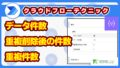
実際に実行してみると、正しく2つのオブジェクト配列が結合できていることが確認できます。そして重要なのは、重複したデータもそのまま結合できていることです。
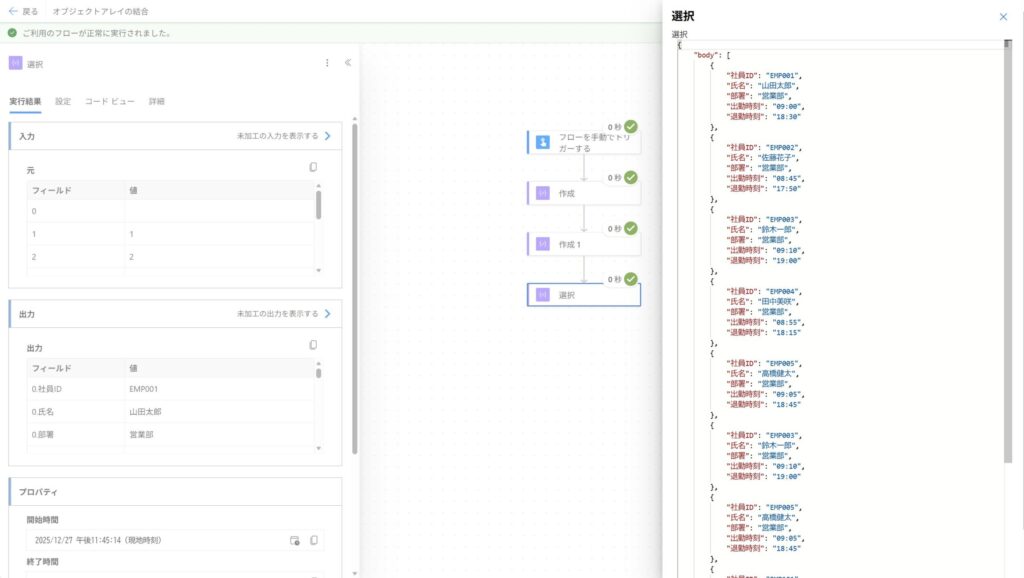
鈴木一郎さんと高橋健太さんのデータが両方の配列に含まれていましたが、union関数とは違い、重複を削除せずに全10件のデータが取得できています。
まとめ
いかがでしたでしょうか?
Power Automateで配列を全件結合する際のポイントは以下の通りです:
- union関数は重複を削除するため、全件結合には不向き
- Selectアクション + range関数で全件結合が可能
if関数とless関数で条件分岐し、適切な配列から要素を取得- 2つ目の配列からの取得時は
sub関数でインデックスを調整
この方法を使えば、Apply to eachを使わずに効率的に配列を結合できます。大量のデータを扱う場合でも、パフォーマンスが良いのでおすすめです。
ぜひ実務で試してみてください。参考になれば幸いです!

コメント