







Power Automateで全角のテキストを半角へ変換したいのに、思ったように処理できず困ってしまったことはありませんか?

実は、ちょっとした工夫を入れるだけで、とてもシンプルに変換できるようになります。ここでは、その手軽な方法を紹介していきます。
マッピング表を使って変換を制御する
まず押さえておきたいのが、全角→半角への対応を定義したマッピング表を用意するという考え方です。
Power Automateでは配列(JSON)を使って左側を「変換前」、右側を「変換後」とするだけで準備ができてしまいます。
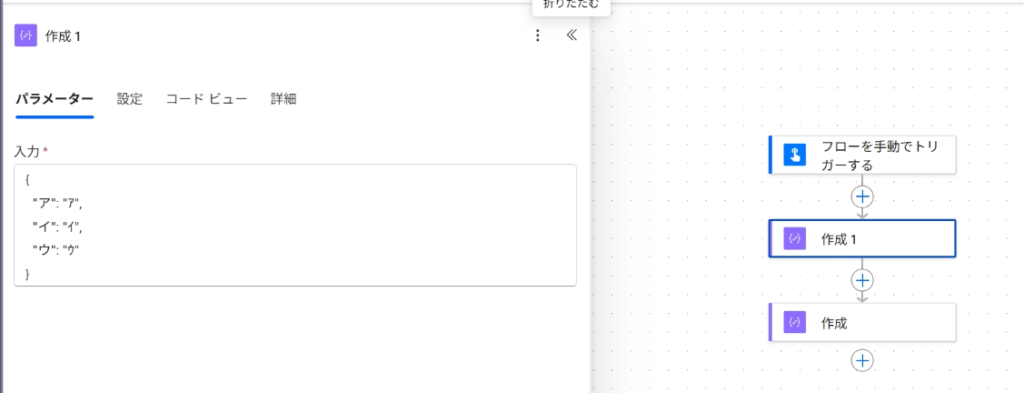
以下のようなリストが必要になります。以下は全角カタカナを半角カタカタに変換するマッピングです。
{"ア":"ア","イ":"イ","ウ":"ウ","エ":"エ","オ":"オ",
"カ":"カ","キ":"キ","ク":"ク","ケ":"ケ","コ":"コ",
"サ":"サ","シ":"シ","ス":"ス","セ":"セ","ソ":"ソ",
"タ":"タ","チ":"チ","ツ":"ツ","テ":"テ","ト":"ト",
"ナ":"ナ","ニ":"ニ","ヌ":"ヌ","ネ":"ネ","ノ":"ノ",
"ハ":"ハ","ヒ":"ヒ","フ":"フ","ヘ":"ヘ","ホ":"ホ",
"マ":"マ","ミ":"ミ","ム":"ム","メ":"メ","モ":"モ",
"ヤ":"ヤ","ユ":"ユ","ヨ":"ヨ",
"ラ":"ラ","リ":"リ","ル":"ル","レ":"レ","ロ":"ロ",
"ワ":"ワ","ヲ":"ヲ","ン":"ン",
"ガ":"ガ","ギ":"ギ","グ":"グ","ゲ":"ゲ","ゴ":"ゴ",
"ザ":"ザ","ジ":"ジ","ズ":"ズ","ゼ":"ゼ","ゾ":"ゾ",
"ダ":"ダ","ヂ":"ヂ","ヅ":"ヅ","デ":"デ","ド":"ド",
"バ":"バ","ビ":"ビ","ブ":"ブ","ベ":"ベ","ボ":"ボ",
"パ":"パ","ピ":"ピ","プ":"プ","ペ":"ペ","ポ":"ポ",
"ァ":"ァ","ィ":"ィ","ゥ":"ゥ","ェ":"ェ","ォ":"ォ",
"ャ":"ャ","ュ":"ュ","ョ":"ョ","ッ":"ッ"}動画では例として、
- あ → ア
- い → イ
- う → ウ
という3つだけを扱っていますが、必要に応じて増やすことで、さらに多くの文字にも対応できるようになります。
chunk関数でテキストを1文字ずつに分割する
次に、変換対象のテキストを1文字ごとに扱えるようにしていきます。
Power Automateには、任意の文字数で分割できる chunk() 関数があり、これを活用することで 一文字単位の配列 を簡単に作ることができます。
chunk(<変換したいテキスト>, 1)この配列が後の変換処理のベースになります。
Selectアクションでマッピング表を参照する
ここからが少し工夫のポイントです。
Power Automateには「Select」アクションがあり、配列の中身を別の値に置き換える処理を簡単に記述できます。
ただし、そのまま使うと「キー」を持ったオブジェクトが生成されてしまうため、
マップを設定するときにテキストモードに切り替えてキーを持たない形にしておくのが大事なポイントです。
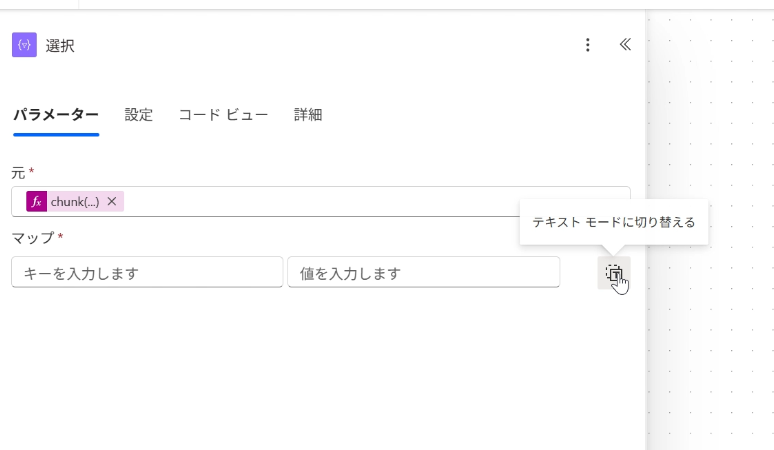

次に、マッピング表の列名を指定すると、
「この文字に対応する半角の値」
を取得できるようになります。
変換対象の文字は配列の内容なので、item() を使って次のように指定します。
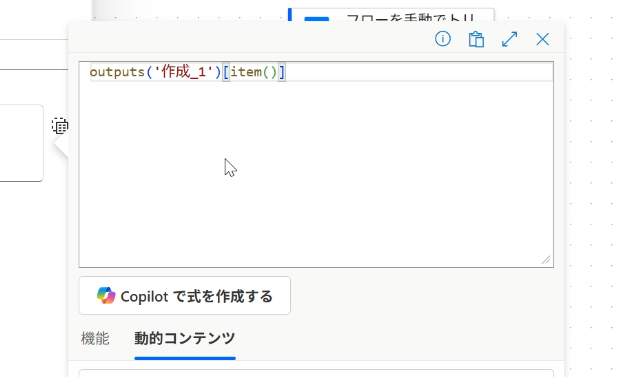
これで1文字ずつ、マッピング表の値に変換されていきます。
join関数で配列をテキストに戻す
Selectアクションを実行すると、半角への変換自体は完了していますが、まだ「配列」の状態になっています。
そこで、join() 関数を使ってテキストに戻していきます。
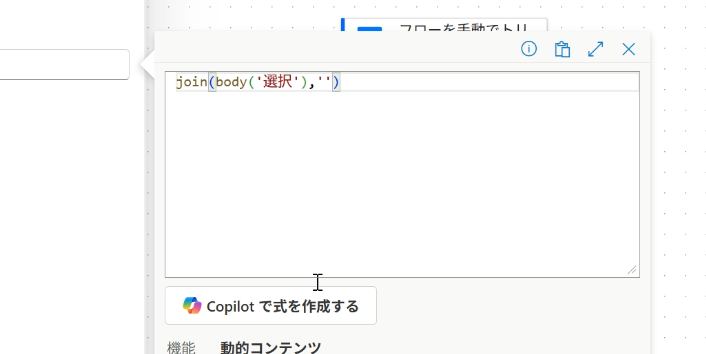
区切り文字が不要な場合は、''(シングルクォーテーション2つ)を指定すればOKです。
なお、最初に「テキストモード」を使ってキーを作らないようにしたのは、ここで余計な処理を書かずに済むようにするためです。
実際に動作を確認すると…
最後にフローを実行してみると、しっかり全角から半角へ変換されていることが確認できます。
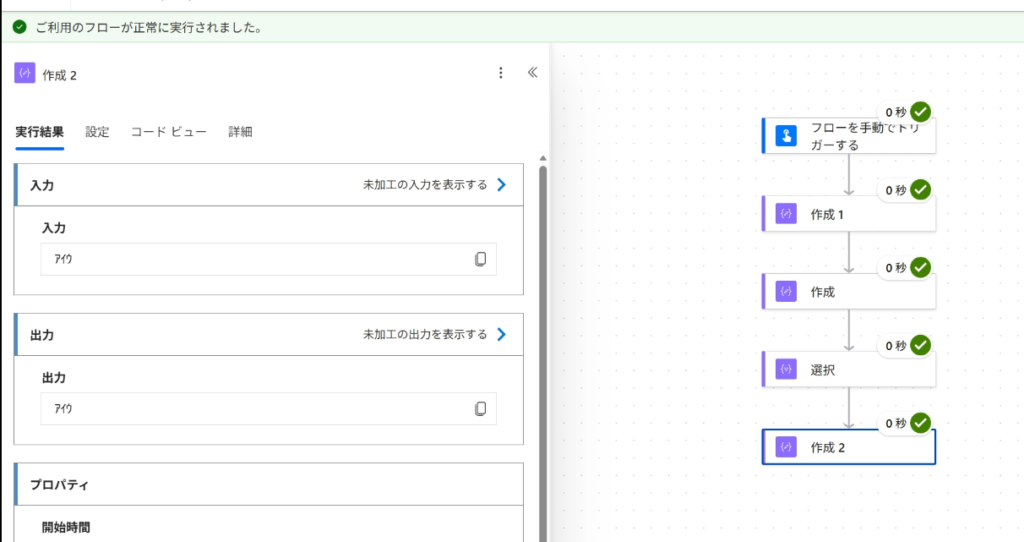
ただし、逆方向の半角→全角への変換は濁点半濁点の処理が必要になるため、今回より少し複雑な処理になります。このあたりは注意しておきたいポイントですね。
いかがでしたでしょうか?
Power Automateでも、マッピング表とSelectアクションをうまく組み合わせることで、繰り返し処理なしのシンプルな全角→半角変換が実現できます。
ぜひ今回の方法を参考に、さまざまなテキスト変換に活用してみてください。


コメント